


STRUCTURED DATA
FROM ANY PUBLIC URL
Point our API at any target and receive clean JSON or CSV. Titan handles IP rotation, fingerprint evasion, CAPTCHA defense, headless rendering, and retries automatically. 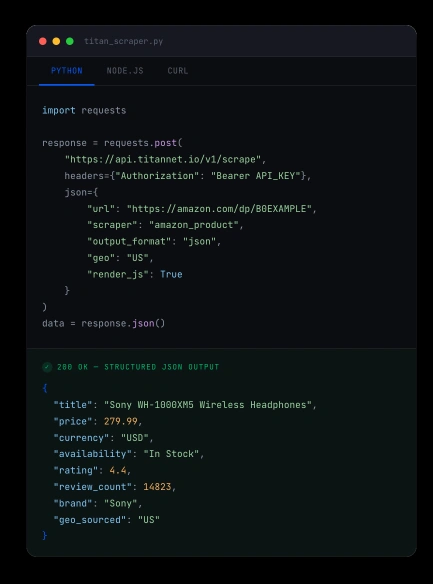
Infrastructure
CLOUD INFRASTRUCTURE BUILT
FOR DATA COLLECTION
AUTOMATIC
UNBLOCKING
Residential IP rotation, browser fingerprint simulation, header spoofing, and retry logic on block detection. No configuration required.
HEADLESS
RENDERING
Full JavaScript execution for SPAs, React and Vue frontends, infinite scroll, and lazy-loaded content without provisioning browser clusters.
STRUCTURED
OUTPUT
Receive clean JSON or CSV with normalized field schemas. Enterprise scrapers ship with custom definitions aligned to your data warehouse.
Scraper Library
INDUSTRY-SPECIFIC SCRAPING SOLUTIONS
Amazon
Scrape product data, prices, and reviews from the world's largest marketplace.
Temu
Extract product listings and competitive pricing data from Temu's global platform.
Shopee
Collect marketplace data from Southeast Asia's leading e-commerce platform.
Trusted By Customer-Lead Product Companies


























Use Cases
PURPOSE-BUILT WEB DATA SOLUTIONS FOR AI, E-COMMERCE, AND ENGINEERING
PRICING
INTELLIGENCE
Product pricing, availability, reviews, and seller data from Amazon, Temu, Shopee, and eBay. Power repricing engines, competitive monitors, and catalog enrichment workflows.
SERP
MONITORING
Ranking data, featured snippet tracking, ad placement monitoring, and keyword intelligence across Google, Bing, DuckDuckGo, and Yandex — geo-localized to any market.
BUSINESS
INTELLIGENCE
Professional profiles, company records, job listings, and hiring velocity signals for sales intelligence, lead enrichment, and market research pipelines.
How It Works
CUSTOM ENTERPRISE INTEGRATION
IN DAYS, NOT MONTHS
CLAIM YOUR FREE
DEVELOPER CREDITS
Submit target URLs and extraction options through the API — specifying scraper type, output format, geo-target, and delivery preference. Single URLs or bulk batches accepted. Start immediately with 2,000 free credits.
TITAN COLLECTS
THE DATA
Titan manages proxy routing, browser rendering, anti-bot evasion, CAPTCHA resolution, selector execution, retries, and field normalization. No infrastructure on your side. Enterprise clients receive an implementation report within 7 days.
RECEIVE STRUCTURED
OUTPUT
Retrieve clean JSON or CSV via API response, webhook callback, or cloud storage delivery — ready for your data warehouse, application, or AI pipeline. We work with you to complete the full integration.
Start with a 10 TB Evaluation Dataset
Validate our pipeline quality before moving to production scale.
Technical Consultation
Brief meeting with our engineers to define your data requirements and delivery targets.
Evaluation Agreement
Secure the 10 TB evaluation window and setup cloud delivery permissions (S3/GCS/Azure).
Data Delivery
Receive your structured dataset and full technical support during the analysis phase.
Geographic Coverage
GLOBAL EDGE ROUTING ACROSS 195 COUNTRIES
Collect localized prices, geo-restricted content, and market-specific search results from any country or city. Titan routes requests through residential IPs in the target region.












Why Titan
PURPOSE-BUILT FOR TEAMS THAT NEED CUSTOM EXTRACTION AT SCALE
Generic scraping APIs provide infrastructure. Titan pairs that infrastructure with enterprise-built, domain-specific scrapers — maintained by our team, not yours.
PRICING
START FREE.
SCALE ON DEMAND.
All plans include full web scraping capabilities, automatic unblocking, and structured output. No credit card required to start.
Starter
2,000 Credits/Month
- check_circle Full web scraping capabilities
- check_circle Access to global residential proxies
- check_circle JSON & CSV export
- check_circle 100 concurrent sessions
- check_circle Community support
No credit card required
Pro
10,000 Credits/Month
- check_circle Advanced scraping features
- check_circle Geo-targeted and rotating residential proxies
- check_circle Seamless API integrations
- check_circle 1,000 concurrent proxy sessions
- check_circle 24/7 Priority support
No credit card required
Enterprise
100,000+ Credits/Month
- check_circle Custom web scrapers
- check_circle Dedicated infrastructure
- check_circle Custom integrations
- check_circle 30,000+ concurrent proxy sessions
- check_circle 24/7 priority support
No credit card required
SCRAPER API FAQ
Titan's scraper API resolves hCaptcha, reCAPTCHA v2 and v3, Cloudflare Turnstile, and custom bot challenges automatically with no third-party solver billing required. Every request is routed through web scraping APIs backed by 4M+ residential IPs with browser fingerprint emulation, header spoofing, headless rendering, and retry logic built in. Your engineering team sends the URL and receives clean data. Titan handles everything in between.
The Scraper API is built for developers and engineering teams that want to integrate data collection programmatically into their own applications, pipelines, or automation workflows. You submit URLs via API call and receive structured data back. The No-Code Web Scraper is for non-technical teams that want to build and run scrapers through a visual interface without any coding. Both run on the same infrastructure with identical proxy networks and success rates.
The free Starter plan gives you 2,000 credits per month with no credit card required. Credits are consumed per API request, so the free tier is enough to test the scraper API across multiple websites, validate output formats, and evaluate integration before scaling. Full web scraping capabilities, global residential proxy access, and JSON and CSV export are all included on the free plan. Web scraping API pricing scales from there based on request volume.
Yes. Titan's scraper API includes full headless rendering for JavaScript-heavy sites, single-page applications built on React or Vue, infinite scroll pages, and lazy-loaded content. This is handled at the infrastructure level without requiring you to provision or manage browser clusters. You submit the URL and specify rendering requirements in the API call, and Titan returns the fully rendered page content as structured output.
Titan's web scraping APIs return clean JSON or CSV with normalized field schemas. For delivery, you can retrieve data via API response, webhook callback, or direct cloud storage delivery to AWS S3, Google Cloud Storage, and Azure Blob. Enterprise clients receive structured data extraction API pricing that includes custom field definitions aligned to their data warehouse schemas, making integration straightforward for teams with existing pipeline infrastructure.
Yes. Titan's ecommerce scraping API and all other scraper products support geo-targeted routing through residential IPs across 195 countries with city-level precision in major markets. You specify the target country or city in the API call, and Titan routes the request through a residential IP in that location. This enables collection of localized pricing, geo-restricted content, and market-specific search results that would be inaccessible from a single server.
Titan differs from Bright Data and Oxylabs in a few important ways. Titan's infrastructure runs on a decentralized DePIN node network rather than centralized data centers, which enables significantly lower pricing. Titan also includes pre-built, domain-specific scrapers maintained by its own team, where most API-only tools provide generic HTML extraction only. CAPTCHA resolution is included at no extra charge, city-level geo-targeting spans 195 countries, and a free tier with 2,000 credits requires no credit card to start.
Yes. Titan's scraper API supports bulk URL submission, allowing you to send batches of URLs in a single call for parallel processing. Enterprise plans include high-concurrency extraction with dedicated session pools, making bulk collection significantly faster than sequential single-URL requests. This is particularly useful for large-scale ecommerce scraping API workflows that need to monitor thousands of product pages or listings simultaneously.
The legal considerations for scraping web data for LLM training center on three areas: whether the data is publicly available, the terms of service of the source website, and how the collected data is used downstream. Titan collects only publicly available content from public-facing URLs and does not access login-gated or private data. All residential IPs are sourced through an opt-in, consent-based node network. For teams building LLM training datasets, Titan recommends consulting legal counsel on specific use cases, particularly where source terms of service explicitly restrict automated collection.
BUILD RELIABLE
EXTRACTION
INTO YOUR PRODUCT
Start with free credits or talk to an engineer about custom scrapers and enterprise-scale API workflows.






 Support
Support



